Using Span and ArrayPool to save £200k+ a year
As the title suggests, this post is going to cover the success we've had in adopting the usage of Span / Memory and ArrayPool in one of our core libraries which is used extensively across our systems.

I've been meaning to write about this for a while, but life gets in the way of plans hey.
As the title suggests, this post is going to cover the success we've had in adopting the usage of Span / Memory and ArrayPool in one of our core libraries which is used extensively across our systems.
The Library
So unfortunately, as this library is proprietary and closed source, I won't be able to include too much detail about the code itself, but I'll try to include code that represents the before and after states that resulted in these savings.
This library has been in use at my employer since the very early days of .Net Framework, with the code remaining largely unchanged since it was first written. It is used across hundreds of servers to call into our core system which is even older. The core system is essentially a heavily customized version of a Unix mainframe system from the 70s, and this library allows other systems that are written in .NET to talk to it.
Packet Parsing
While we adopted the usage of Span /Memory and ArrayPool in multiple parts of the library, the most impactful was the low level parts of the library that deal with the underlying connection, sending packets to and receiving packets from the core system.
Below is a representation of how this code worked before I started introducing the goodness.
internal class Message
{
private byte[] header;
private byte[] arguments;
private byte[] data;
private byte[] dataBuffer;
private int dataBufferSize;
public Message()
{
header = new byte[24];
arguments = new byte[4096];
data = new byte[8192];
InitHeader();
Reset();
compressionThreshold = 0;
}
private void InitHeaders()
{
for (var i = 0; i < header.Length; i++)
{
header[i] = 0;
}
header[0] = 111;
// more init code...
}
// various other methods
private void ResetData(int length)
{
// other stuff ...
data = new byte[length];
}
public char[] ReadChars(int index)
{
// other stuff ....
return new string(data.ToCharArray(), start, index).ToCharArray();
}
public double ReadDouble(int index)
{
// other stuff...
var array = new byte[8];
Array.Copy(arguments, sourceIndex, array, 0, 8);
Array.Reverse(array, 0, 8);
return BitConverter.ToDouble(array, 0);
}
public double[] ReadDoubles(int index)
{
// other stuff...
for (var i = 0; i < length; i++)
{
var array = new byte[8];
Array.Copy(arguments, sourceIndex, array2, 0, 8);
Array.Reverse(array, 0, 8);
array[i] = BitConverter.ToDouble(array2, 0);
}
return result;
}
public byte[] ReadBytes(int index)
{
// other stuff...
var array = new byte[length];
Array.Copy(data, sourceIndex, array, 0, length);
return array;
}
public void Receive(NetworkStream receiveStream)
{
header = new byte[24];
receiveStream.Read(header, 0, header.Length);
dataBufferSize = GetDataLength();
ArgumentCount = GetArgumentCount();
dataBuffer = new byte[dataBufferSize]
var offset = 0;
int read;
do
{
read = receiveStream.Read(dataBuffer, offset, dataBufferSize - offset);
offset += read;
} while (read != 0 && (receiveStream.DataAvailable || offset < dataBufferSize));
// other stuff ...
}
public void Send(NetworkStream sendStream)
{
// other stuff...
sendStream.Write(header, 0, header.Length);
sendStream.Write(dataBuffer, 0, dataBuffer.Length);
sendStream.Flush();
}
public static char[] ToCharArray(byte[] chars)
{
var array = new char[chars.Length];
for (var i = 0; i < chars.Length; i++)
{
array[i] = (char)chars[i];
}
return array;
}
}I wrote this in notepad, so it likely doesn't compile or has obvious errors I've missed, but it should give a good idea of how the packet parsing code was originally written.
Now something I'm sure will stick out with this code, is just how many of these methods are creating new T[], what is not directly shown here is that lots of other methods also made copies of these arrays for doing their processing.
The following code represents what it looked like after I had made the changes to introduce Span/ ArrayPool
[StructLayout(LayoutKind.Sequential)]
internal struct Header
{
public byte Version;
public int DataLength;
// other parts of the header...
}
internal class Message
{
private Header header;
private byte[] arguments;
private byte[] data;
// new int to track the underlying size of the data
// as ArrayPool returns arrays that can be bigger
private int dataSize;
private byte[] dataBuffer;
private int dataBufferSize;
internal Message()
{
header = new();
arguments = ArrayPool<byte>.Shared.Rent(4096);
data = ArrayPool<byte>.Shared.Rent(8192);
Reset();
}
private void ResetData(int length)
{
// other stuff....
ArrayPool<byte>.Shared.Return(data);
data = ArrayPool<byte>.Shared.Rent(length);
return;
}
// ReadChars, ReadDouble and ReadDoubles were all removed, as they all became Span.Slice().To<T> at the call sites
public (int Length, byte[] Bytes) ReadBytes(int index)
{
var array = ArrayPool<byte>.Shared.Rent(length);
Array.Copy(data, sourceIndex, array, 0, length);
return (length, array);
}
public async Task ReceiveAsync(NetworkStream receiveStream)
{
ReadHeader();
dataBufferSize = GetDataLength();
ArgumentCount = GetArgumentCount();
dataBuffer = ArrayPool<byte>.Shared.Rent(dataBufferSize);
var offset = 0;
int read;
do
{
read = await receiveStream.ReadAsync(dataBuffer, offset, dataBufferSize - offset);
offset += read;
} while (read != 0 && (receiveStream.DataAvailable || offset < dataBufferSize));
// other stuff ....
ArrayPool<byte>.Shared.Return(dataBuffer);
void ReadHeader()
{
// cant you span in async context, so stick it in a local method
var headerStack = stackalloc byte[24];
receiveStream.Read(headerStack);
packetHeader = SpanToPacketHeader(headerStack);
}
}
public async Task SendAsync(NetworkStream sendStream)
{
// at the time I originally wrote this, it wasn't 'possible' (at least that I could find) to get the span into a ReadOnlyMemory<byte> that WriteAsync requires, so its sync
sendStream.Write(PacketHeaderToSpan());
await sendStream.WriteAsync(dataBuffer, 0, dataBufferSize);
await sendStream.FlushAsync();
ArrayPool<byte>.Shared.Return(dataBuffer);
}
private ReadOnlySpan<byte> HeaderToSpan()
{
var span = MemoryMarshal.CreateSpan<Header>(ref header, 1);
return MemoryMarshal.Cast<Header, byte>(span);
}
private Header SpanToHeader(ReadOnlySpan<byte> bytes)
{
return MemoryMarshal.Cast<byte, Header>(bytes)[0];
}
public void Dispose()
{
if (data is not null && data != Array.Empty<byte>())
{
ArrayPool<byte>.Shared.Return(data);
}
if (arguments is not null && arguments != Array.Empty<byte>())
{
ArrayPool<byte>.Shared.Return(arguments);
}
}
}
The first thing you will likely notice, is that the header is no longer a byte[] but is now a struct. Not only did this remove the array allocation, make the code more readable and easier to understand by people who haven't read the spec sheet, but also removed all of the bit twiddling that was in use previously mapping the various types across multiple bytes. I added the HeaderToSpan and SpanToHeader methods just to make the casting back and forth easier at the various call sites.
Everywhere else that was doing new byte[] has been updated to use ArrayPool, and where that was being passed between methods, a new int was introduced to track the original data size as the ArrayPool rented byte[] is almost never the exact size requested. I originally relied on ArrayPool as the original code appeared to have paths that could result in varying sized buffers being required. However, after these changes and various others to modernize the library, it has become apparent that is not the case anymore (and possibly never was) so I could have simplified things a bit by having a custom FixedSizeArrayPool to ensure the buffer was always exactly the size requested (which I use in some other projects where I know that the required buffer size never changes) and thus not need to track the size seperately.
The Result
Even I was suprised with the results, while I can't share the real benchmarks, I can say that an average request to the core system I was using for the benchmark went from 600-700ms to execute with almost 1MB of memory allocated, to 200-300ms with 0 allocations. Mutliplying this improvement across our hundreds of systems using this library, was obviously going to make a massive impact to our cloud costs, as CPU cycles and Memory workingsets are what you pay for in the cloud.
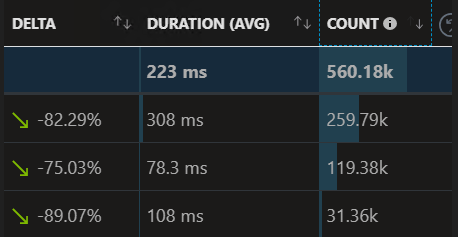
Sure enough, the first system we deployed the updated library to showed a drastic improvement. The container instance memory usage was cut in half, the system scaled back the total number of instances as it was now able to handle much more load per instance, and pretty much every metric on our monitoring went green when compared to before the release, which is the image at the top of the post.
Here's a bigger version that shows just how across the board the improvement was.
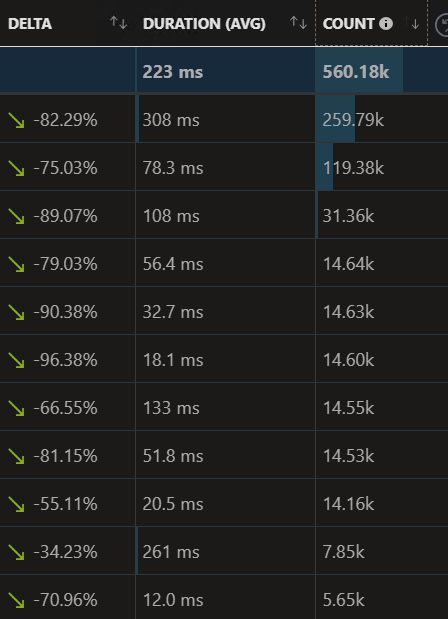
I've already estimated we will easily save 200k on cloud costs this year alone, and likely more through a reduction in the load on the core system due to the connections being closed much more quickly, so its free to do other work it used to spend waiting for the .NET code to finish processing and close.
It was even noticed by the end users. One user logged a ticket insisting something must be wrong, as the thing they had been doing for years that 'always took at least 5 mins to run' was suddenly completing in less than a min, so surely it wasn't actually processing all the data anymore. Turns out that user had been doing something that made thousands of little requests, which with the increased connection speed really benifited.
In my next post, I plan to cover some of my own applications that have been using these methods to make blazingly fast .NET apps, which I'll be able to share alot more of the actual implmentation for.